The following code you can call in generic insert.You can just pass the XML in predefined format as given below and will insert the following values in column Any further improvements appreciated here
NOTES
<Params> and </params> will contain 1 row
ColumnName-pass column value
ColumnValue-pass column value
XML FORMAT
<DAL>
<TableName TableIdentifier="TABLE NAME HERE">
<Params>
<Param ColumnName="ColumnName" ColumnValue="ColumnValue"/>
<Param ColumnName="ColumnName" ColumnValue="ColumnValue"/>
</Params>
<Params>
<Param ColumnName="ColumnName" ColumnValue="ColumnValue"/>
<Param ColumnName="ColumnName" ColumnValue="ColumnValue"/>
</Params>
</TableName>
</DAL>
PROCEDURE
set ANSI_NULLS ON
set QUOTED_IDENTIFIER ON
go
ALTER PROCEDURE [dbo].[proAddGenericCategory]
@varGenericXML XML
AS
BEGIN
DECLARE @cmd NVARCHAR(4000);
DECLARE @MakeStament NVARCHAR(4000);
DECLARE @MakeColumnString VARCHAR(4000);
DECLARE @MakeValueString VARCHAR(4000);
DECLARE @lColumnName VARCHAR(256);
DECLARE @ColumnName VARCHAR(256);
DECLARE @lColumnValue VARCHAR(256);
DECLARE @NoOfRowsOfTemporaryTable SMALLINT;
DECLARE @lcounter SMALLINT;
DECLARE @lTableName VARCHAR(256);
DECLARE @NoOfColumns SMALLINT;
DECLARE @lColumnCounter VARCHAR(4000);
DECLARE @StoreXML TABLE
(
SerialNo SMALLINT IDENTITY(1,1),
ColumnName VARCHAR(256),
ColumnValue VARCHAR(256)
);
SET NOCOUNT ON;
BEGIN TRY
BEGIN TRANSACTION GenericInsert
BEGIN
SET @lcounter = 1;
SET @lColumnCounter = 1;
SET @MakeColumnString='';
SET @MakeValueString='';
SELECT @lTableName = Table1.Column1.value('(@TableIdentifier)[1]','VARCHAR(256)')
FROM @varGenericXML.nodes('/DAL/TableName') as Table1(Column1);
SELECT @NoOfColumns=Table1.Column1.value('count(Params/Param[1])','VARCHAR(20)')
FROM @varGenericXML.nodes('/DAL/TableName') as Table1(Column1);
WHILE(@lColumnCounter <= @NoOfColumns)
BEGIN
SET @cmd='SELECT Table1.Column1.value('+'''(@ColumnName)[1]'''+','+'''VARCHAR(256)'''+'),
Table1.Column1.value('+'''(@ColumnValue)[1]'''+','+'''VARCHAR(256)'''+')FROM
@varXML.nodes('+'''/DAL/TableName/Params['+@lColumnCounter+']/Param'''+') as Table1(Column1)';
INSERT INTO @StoreXML EXEC sp_executesql @cmd,N'@varXML XML',@varXML=@varGenericXML;
SELECT @NoOfRowsOfTemporaryTable = MAX(SerialNo) FROM @StoreXML;
WHILE (@lCounter <= @NoOfRowsOfTemporaryTable)
BEGIN
SELECT @lColumnName = ColumnName,
@lColumnValue = ColumnValue
FROM @StoreXML
WHERE SerialNo = @lCounter;
SET @MakeColumnString = @MakeColumnString + @lColumnName +',';
SET @MakeValueString = @MakeValueString + ''''+@lColumnValue+''''+',';
SET @lCounter = @lCounter + 1;
END
SET @MakeColumnString= SUBSTRING(@MakeColumnString,1,LEN(@MakeColumnString)-1);
SET @MakeValueString= SUBSTRING(@MakeValueString,1,LEN(@MakeValueString)-2)+'''';
SET @MakeStament = 'INSERT INTO '+@lTableName+' ('+@MakeColumnString +')VALUES('+ @MakeValueString +');';
DELETE FROM @StoreXML;
EXECUTE(@MakeStament);
SET @MakeColumnString='';
SET @MakeValueString='';
SET @lColumnCounter = @lColumnCounter + 1;
END
COMMIT TRANSACTION GenericInsert;
SELECT 'True' AS RESULT;
END
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION GenericInsert;
SELECT ERROR_MESSAGE() AS RESULT;
END CATCH
END
Thanks and regards
Kamesh Shah
Wednesday, December 15, 2010
Execution Plan of query in sql server
When you submit a query sql server what steps it process?
First query is process in relational engine then execution plan which is generated is executed in storage engine
Plan is generated in binary format non readable
- FROM clause
- WHERE clause
- GROUP BY clause
- HAVING clause
- SELECT clause
- ORDER BY clause
Plans are generated for DML statements
FROM: First it will come into from clause that time only if you exclude the rows by using ON conditions then in the second phase it will come into where clause that time less rows will be there to process
WHERE: When query will be in where clause at that time will remove unwanted rows and then they are grouped
and then it will carry on with select part project the columns and will order by in proper sequence if mentioned
How to Get servername,instancename,hostname
To Get the name of server execute this query: SELECT SERVERPROPERTY(“MachineName”)
To Get the name of the computer running the query: SELECT host_name()
Instance name: SELECT @@ServerName
Some Basic bottomlines how SQL SERVER stores a data
Hi,
While surfing i got this details and very nicely explained what is datapage in sql server?
While surfing i got this details and very nicely explained what is datapage in sql server?
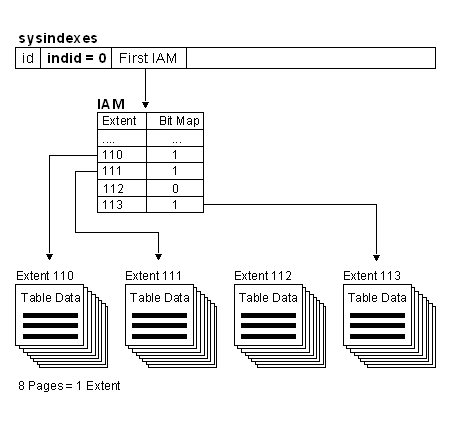
SQL Server Data Structure | ||||||||||||||
Table StructurePages and Extents
Heaps and the Index Allocation Map (IAM)
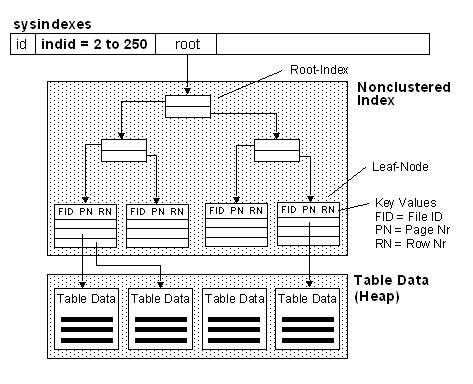
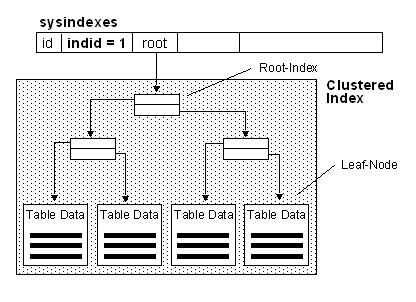
Index Structure
Nonclustered Indexes
Considerations
Clustered Indexes
Considerations
| ||||||||||||||
Subscribe to:
Comments (Atom)